There are thousands of books and documents containing text in endangered languages created by documentary linguists and language education programs, such as language learning textbooks and cultural texts. However, the vast majority are not widely accessible because they exist only as non-digitized printed books and handwritten notes.
We’re building natural language processing (NLP) models to improve the accuracy of Optical Character Recognition (OCR) systems on low-resourced and endangered languages. This enables the extraction of text from these non-digitized documents, converting them into a machine-readable format and making them accessible and searchable online.
📌 Our software is on GitHub: available here.
📌 We’ve also created a benchmark dataset for OCR on endangered languages: available here.
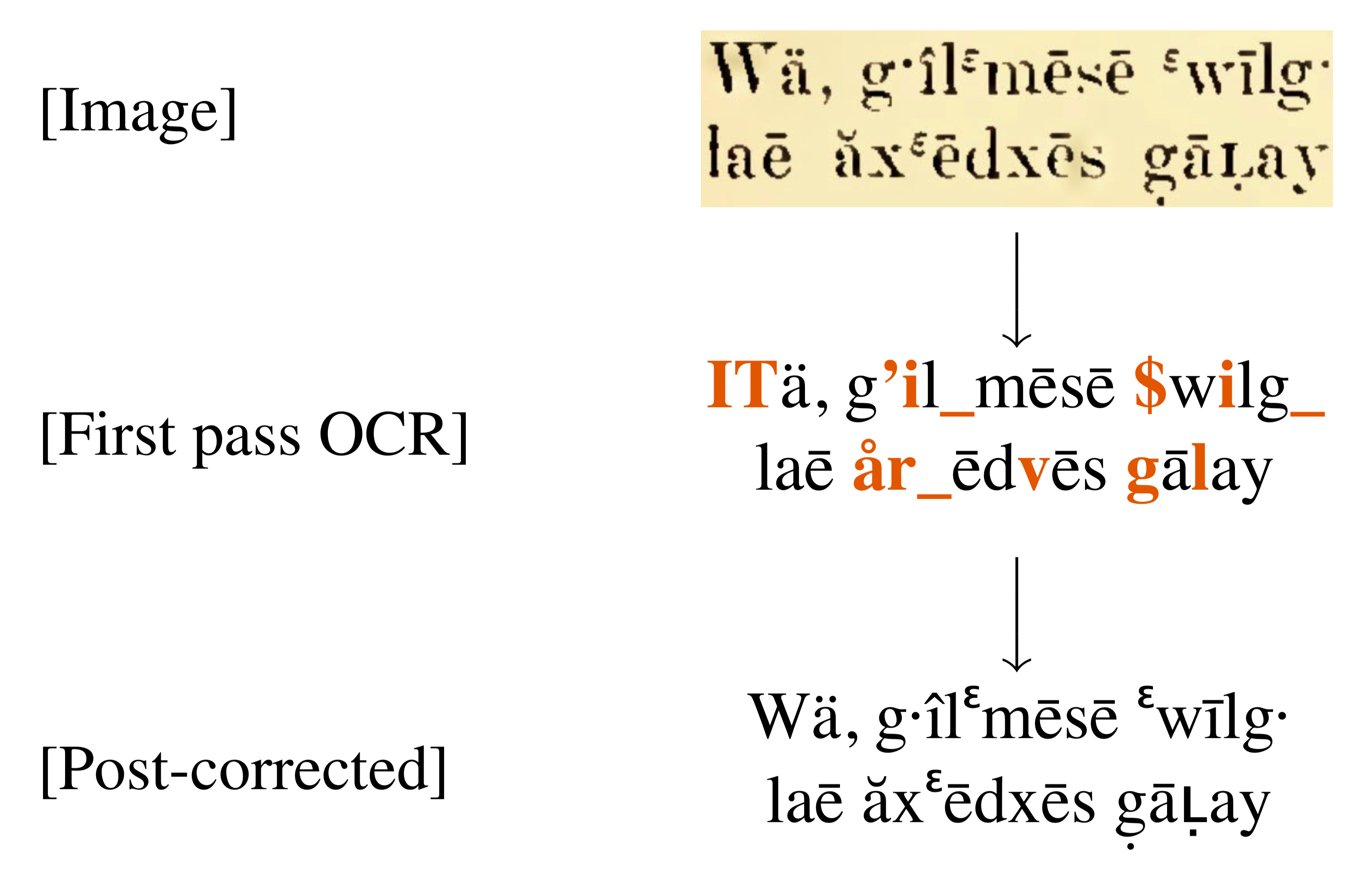 Figure: OCR post-correction on a scanned document that contains text in the endangered language Kwak’wala. The goal of post-correction is to fix the recognition errors made by the first pass OCR system.
Figure: OCR post-correction on a scanned document that contains text in the endangered language Kwak’wala. The goal of post-correction is to fix the recognition errors made by the first pass OCR system.
Our research focuses on improving the results of existing OCR systems using OCR post-correction, where we design models to automatically correct recognition errors in OCR transcriptions.
In our EMNLP 2020 paper, we present:
- A benchmark dataset for OCR and OCR post-correction
- The dataset contains documents in three critically endangered languages: Ainu, Griko, Yakkha.
- An extensive analysis of existing OCR systems
- We show that these systems are not robust to the data-scarce setting of endangered languages.
- An OCR post-correction method adapted to data-scarce settings
- Our method reduces the word error rate by 34%, on average, over a state-of-the-art OCR system.
Our recent TACL 2021 paper improves over our previous work with a semi-supervised OCR post-correction method. The semi-supervised method has two key components:
- Self-training
- This is a simple technique to use unlabeled data by re-training the model on its own predictions.
- Lexically aware decoding
- Self-training often introduces noise into the model through incorrect predictions!
- We reinforce correctly predicted words by combining the neural OCR post-correction model with a count-based language model.
- Joint decoding is implemented using a weighted finite-state automata (WFSA) representation of the LM.
In experiments on four endangered languages, our method improves digitization accuracy over our previous model, with relative error reductions of 15-29%.
More details:
- EMNLP 2020 paper and recorded talk
- TACL 2021 paper and recorded talk.